大一下学期python课程大作业,参考网上源码
概述
- 对数据进行分析和预处理,筛选数据
- 模型训练和参数调整
- 结果输出
- 模型评估
库
import pandas as pd #用于数据读入和处理 |
数据分析
1.ques_info.txt
数据读入和预处理
# 数据集 1 ques_info.txt |
输出结果
9668 |
- 说明:使用dataframe.columns()修改列名,便于后续编辑使用
2.user_info.txt
# 数据集 2 user_info.txt |
输出结果
用户ID 7333 |
结果分析:输出结果为1的项目,创作关键词的编码序列、创作数量等级、创作热度等级、注册类型、注册平台均对结果无影响,删除这几列
for col in user.columns:
if len(user[col].unique())==1:
user.drop([col],axis=1,inplace=True)3.data.txt
data = pd.read_csv("data.txt", sep='\t')
data.columns = "问题ID 用户ID 邀请创建时间 邀请是否被回答".split(" ")4.数据集合并
data = pd.merge(data, user, how='left', on='用户ID')
data = pd.merge(data, ques, how='left', on='问题ID')说明:
- 以data.txt中的内容为基准,整理三个文件中的信息至一个dataframe,其中user与data中的用户ID相对应,ques与data中的问题ID相对应
5.数据集划分
from sklearn.model_selection import train_test_split
train, testd = train_test_split(data, train_size=0.8)
val, testd = train_test_split(testd, train_size=0.5)
y_train = data[:train.shape[0]]['邀请是否被回答'].values
x_train = data[:train.shape[0]].drop(['邀请是否被回答'], axis=1).values
y_val = data[train.shape[0]:train.shape[0] + val.shape[0]]['邀请是否被回答'].values
x_val = data[train.shape[0]:train.shape[0] + val.shape[0]].drop(['邀请是否被回答'], axis=1).values
x_test = data[train.shape[0] + val.shape[0]:].drop(['邀请是否被回答'], axis=1).values
y_test = data[train.shape[0] + val.shape[0]:]['邀请是否被回答'].values
- 以data.txt中的内容为基准,整理三个文件中的信息至一个dataframe,其中user与data中的用户ID相对应,ques与data中的问题ID相对应
将data按8:1:1的比例划分成train、validation、test,其中train用于模型训练,validation用于模型选择和参数调整,test用于对比模型预测和实际值并对模型进行评估
变量处理
时间
data['邀请创建时间-day'] = data['邀请创建时间'].apply(lambda x: float(x.split('-')[0].split('D')[1])) |
- 说明:
- 格式为:D3-H4,分解成天和时两个变量,使用函数split(“-“),并且脱去字母D和H,转成float类型,便于后续的模型训练
- apply函数,功能为将一个siries中的全部元素通过括号内的元素映射成另一个值
话题
ls = [i for i in range(0, data.shape[0])] |
说明
用户关注的话题
- 读入时为字符串,eg.”T1727,T5310,T3402,T916,T1506,T26329,T7293,T18098,T14572,T6657,T56,T50,T68,T148,T89,T38,T5,T32”,利用代码:
a = data.ix[i, "用户关注的话题"].split(",")分解成列表
- 读入时为字符串,eg.”T1727,T5310,T3402,T916,T1506,T26329,T7293,T18098,T14572,T6657,T56,T50,T68,T148,T89,T38,T5,T32”,利用代码:
问题绑定的话题ID
- 同理,利用代码
b = data.ix[i, "问题绑定的话题ID"].split(",")分解成列表,方便与用户关注的话题进行比对
- 同理,利用代码
用户感兴趣的话题
- 格式为 T1:0.2,T2:0.5:T3,-0.3,…,Tn:0.42,利用代码
c = sp_dict(data.ix[i, "用户感兴趣的话题"])分解成字典格式,其中sp_dict函数实现为def sp_dict(a): # 分割字符串成为字典
a = re.split('[,:]', a)
a[1::2] = map(float, a[1::2]) # 将数值字符穿转换为float便于计算
b = dict(zip(a[::2], a[1::2]))# 使用zip函数合成字典
return b
- 格式为 T1:0.2,T2:0.5:T3,-0.3,…,Tn:0.42,利用代码
对每一个问题,对比问题绑定的话题ID列表和用户关注的话题列表,将重合的数目,即对该问题所涉及话题用户的关注个数计入cn1中;对比问题绑定话题ID列表和用户感兴趣的话题程度字典,计算用户对该问题的感兴趣程度,将结果计入cn2中
.ix函数说明:
- 用于同时利用位置和列(行)名进行位置索引
- 使用示例:
data.ix[i, "用户关注的话题"]
其它文字信息
from sklearn.preprocessing import LabelEncoder |
- 说明:
feat列表中为文字信息,利用sklearn.processing中的LabelEncoder对文字信息进行编号,将dataframe转换成纯数字的矩阵,使其可以进行模型训练其它变量
drop_feat = ['问题标题的单字编码序列', '问题标题的切词编码序列',
'问题描述的单字编码序列', '问题描述的切词编码序列',
'问题创建时间', '邀请创建时间', '注册类型', '注册平台',
'用户关注的话题', '问题绑定的话题ID', '用户感兴趣的话题']
data = data.drop(columns=drop_feat, axis=1) - 由前期的数据分析可知
- 信息:创作关键词的编码序列、创作数量等级、创作热度等级、注册类型、注册平台均无法对数据进行区分,没有分析价值,故舍去。
- 信息:问题标题的单字编码序列、问题描述的单字编码序列与切词编码序列携带信息在内容上有一定的重复,为防止模型过拟合,删去。
- 信息:用户关注的话题、问题绑定的话题ID、用户感兴趣的话题、问题创建时间、邀请创建时间 均已在前面的代码中分析过并转化成更适合模型训练的格式,故删去。
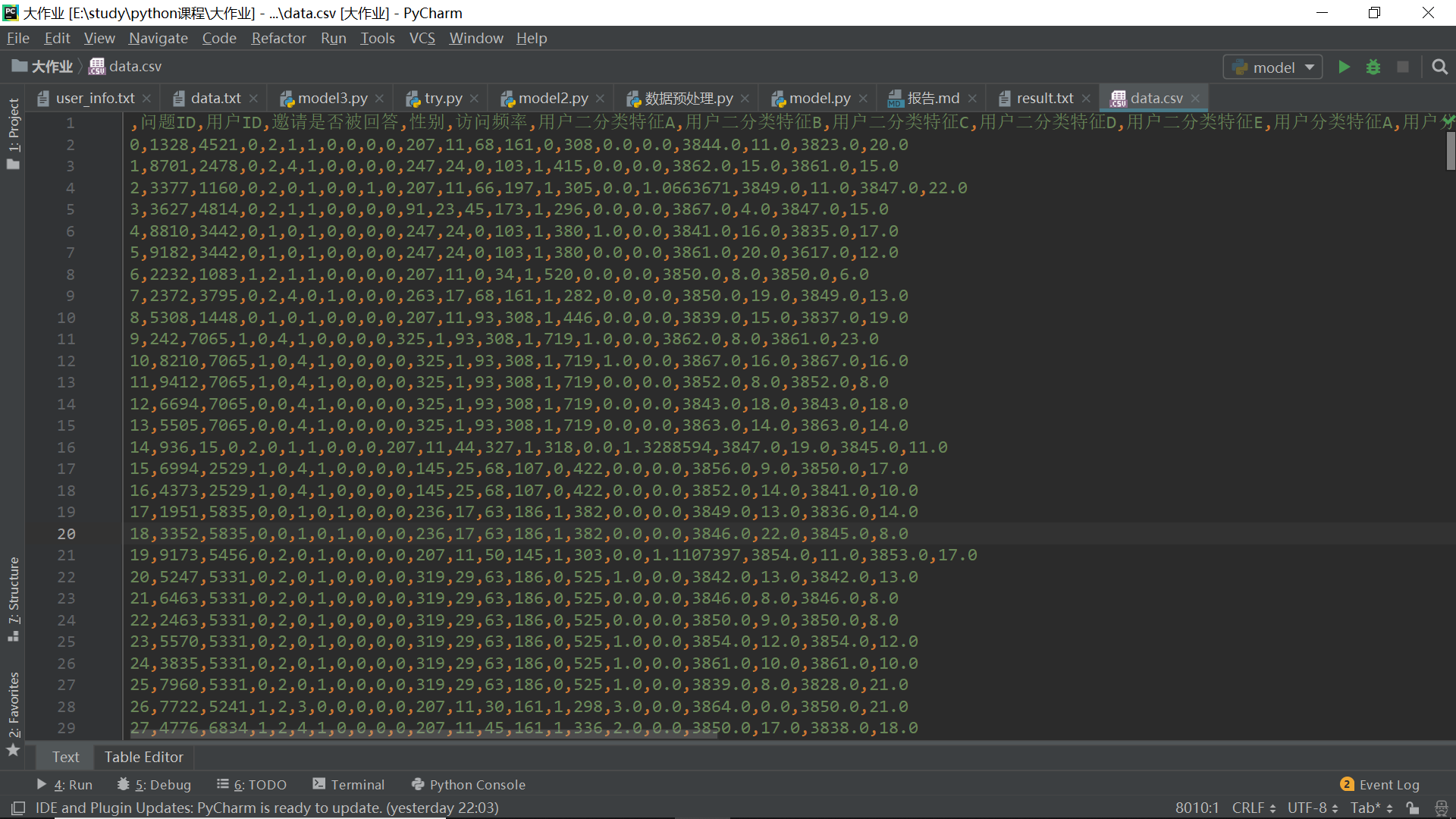
- 经过上述处理,dataframe为图片中的格式:

模型训练和参数调整
import pandas as pd |
- 说明
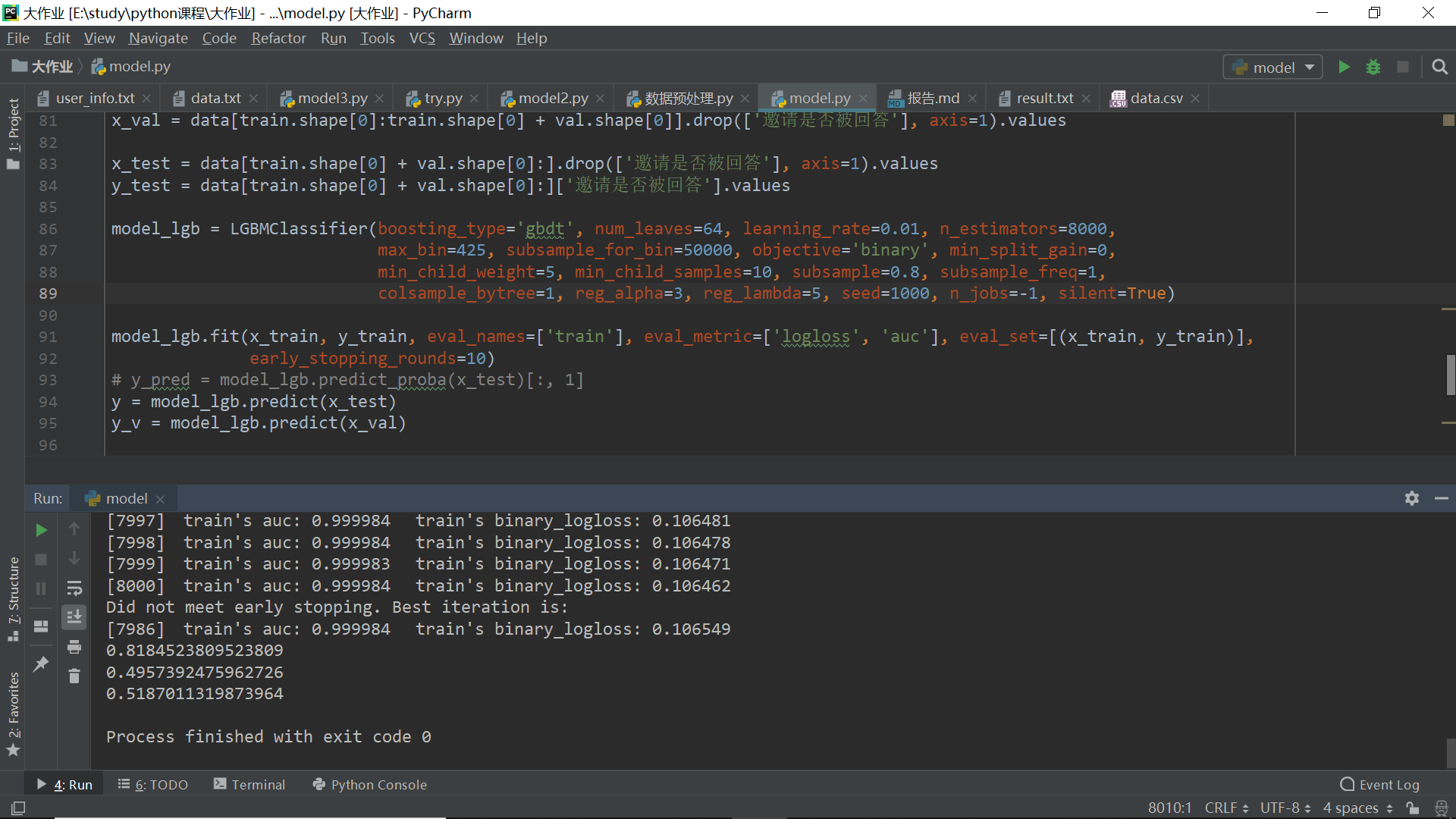
- 使用lightgbm对模型进行训练
- 参数详解:
- LGBMclassifier:
- boosting_type 提升树的类型
- num_leaves 树的最大叶子数,一般为2^(max_depth)
- learning_rate 学习率
- n_estimators 拟合的树的棵树,相当于训练轮数
- max_bin
- 如果需要更快的训练速度,max_bin应设置小一些
- 如果需要较高的准确度,应设置大一些
- subsample_for_bin
- objective 学习任务参数,binary为二分类
- min_split_gain 最小分割增益
- min_child_weight 分支结点的最小权重
- min_child_samples
- subsample 训练样本采样率 行
- subsample_freq 子样本频率
- colsample_bytree 训练特征采样率 列
- reg_alpha L1正则化系数
- re_lambda L2正则化系数
- seed 随机种子数
- n_jobs 并行运行多线程核心数
- silent 训练过程是否打印日志信息
- fit
- early_stopping_rounds=10
- 当eval_matrix在10轮中都没有提升时停止训练
- eval_matrix
- 在lgbm处理二分类问题时,将eval_matrix设定成
eval_metric=['logloss', 'auc'],其中logloss是对数损失函数,auc是ROC曲线下与坐标轴围成的面积,AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低
- 在lgbm处理二分类问题时,将eval_matrix设定成
- early_stopping_rounds=10
- 控制过拟合:
- 降低模型复杂度:max_depth, min_child_weight and gamma
- 对样本随机采样:subsample, colsample_bytree
- 降低学习率,同时相应提高训练轮数
- 决策树类型选择——gdbt
- 是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案
- 适用于二分类问题
- LGBMclassifier:
结果输出
y = model_lgb.predict(x_test) |
模型评估
- 比较test集预测准确度
judge = result.merge(testd, how='left', on='问题ID')
judge['判断是否准确'] = judge[['是否被回答', '邀请是否被回答']].apply(lambda x: x['是否被回答'] == x['邀请是否被回答'], axis=1)
print(list(judge['判断是否准确']).count(True) / len(list(judge['判断是否准确'])))
- auc
from sklearn.metrics import roc_auc_score
# 根据validation的auc评价调整参数
auc_lgbm = roc_auc_score(y_val, y)
print(auc_lgbm)
auc_lgbm_t = roc_auc_score(y_test, y)
print(auc_lgbm_t)
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.



