from selenium import webdriver
import time
import pandas as pd
from flightlinespider import *
import random
class CTSpider(object):
def __init__(self, i):
self.i = 0
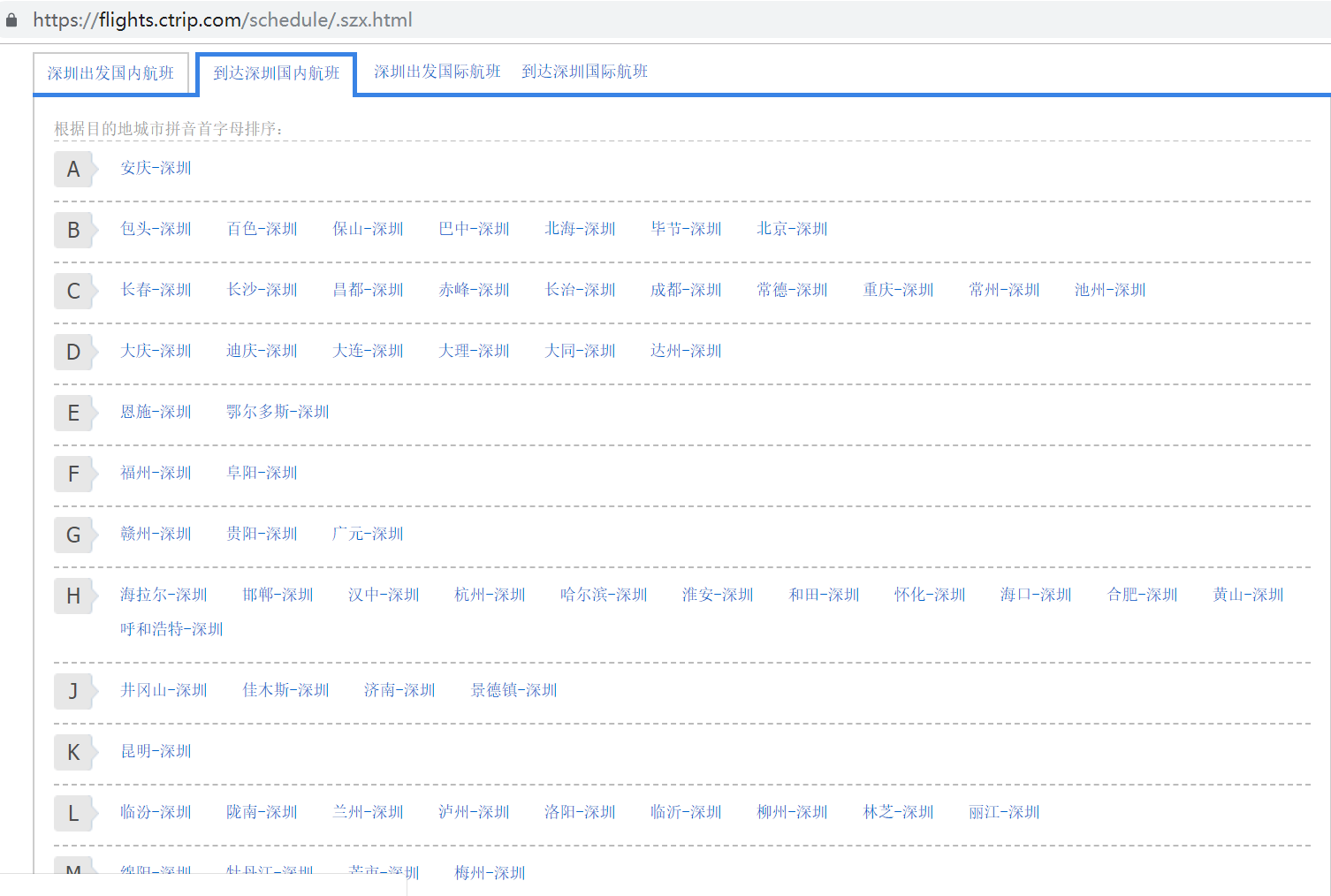
self.url = 'https://flights.ctrip.com/schedule/.szx.html'
self.browser = driver = webdriver.Chrome(
r'D:/anaconda/new/Lib/site-packages/selenium/webdriver/chrome/chromedriver.exe')
self.index = i
def get_html(self):
self.browser.get(self.url)
self.browser.find_elements_by_link_text(route_list[self.index])[0].click()
time.sleep(random.uniform(2, 4))
def parse_html(self):
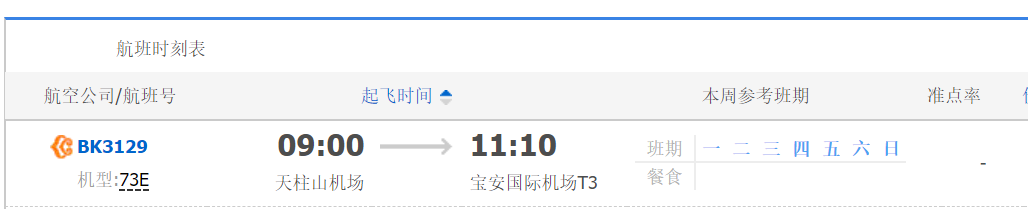
flights = self.browser.find_elements_by_class_name("flight_logo")
flightno_list = []
flight_list = []
for flight in flights:
text = flight.text.split('/n机型:')
flightno_list.append(text[0])
flight_list.append(text[1])
arv = self.browser.find_elements_by_class_name("arrive")
arrive_time = []
arrive_airport = []
for i in arv:
a = i.text.split('/n')
arrive_time.append(a[0])
arrive_airport.append(a[1])
flights = self.browser.find_elements_by_class_name("weeks")
flights = flights[1:]
week_list_mon = []
week_list_tue = []
week_list_wed = []
week_list_thu = []
week_list_fri = []
week_list_sat = []
week_list_sun = []
dic = {0: '一', 1: '二', 2: '三', 3: '四', 4: '五', 5: '六', 6: '日'}
dic_ = {'一': 0, '二': 1, '三': 2, '四': 3, '五': 4, '六': 5, '日': 6}
for flight in flights:
weeks = flight.find_elements_by_class_name("blue")
weekli = []
for i in weeks:
weekli.append(i.text)
m = 0
if dic[m] in weekli:
week_list_mon.append(1)
else:
week_list_mon.append(0)
m = 1
if dic[m] in weekli:
week_list_tue.append(1)
else:
week_list_tue.append(0)
m = 2
if dic[m] in weekli:
week_list_wed.append(1)
else:
week_list_wed.append(0)
m = 3
if dic[m] in weekli:
week_list_thu.append(1)
else:
week_list_thu.append(0)
m = 4
if dic[m] in weekli:
week_list_fri.append(1)
else:
week_list_fri.append(0)
m = 5
if dic[m] in weekli:
week_list_sat.append(1)
else:
week_list_sat.append(0)
m = 6
if dic[m] in weekli:
week_list_sun.append(1)
else:
week_list_sun.append(0)
punc = self.browser.find_elements_by_class_name("punctuality")
punc_list = []
for i in punc:
if i.text != '准点率':
punc_list.append(i.text)
data = {'航班号':flightno_list,'机型': flight_list, '到达时间': arrive_time,
'到达机场': arrive_airport,'周一': week_list_mon, '周二': week_list_tue,
'周三': week_list_wed, '周四': week_list_thu, '周五': week_list_fri,
'周六': week_list_sat, '周日': week_list_sun, '准点率': punc_list}
df = pd.DataFrame(data)
df=df.drop_duplicates()
df.to_csv('Data3.csv', mode='a', header=False)
def main(self):
self.get_html()
self.parse_html()
if __name__ == '__main__':
global route_list
for i in range(0, len(route_list)):
print(i, route_list[i])
spider = CTSpider(i)
spider.main()
|