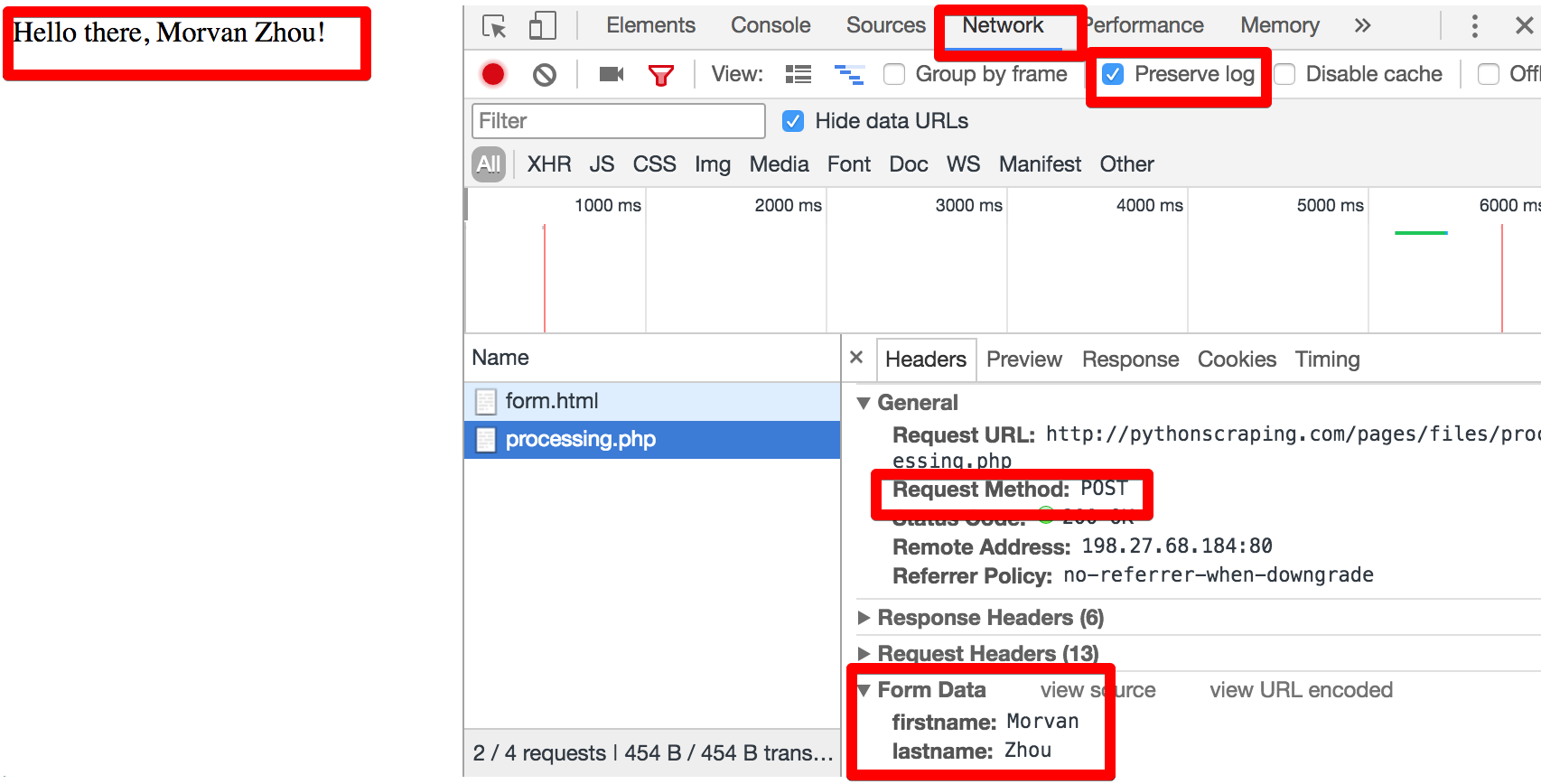
# 用正则表达式匹配tag,筛选信息 import re # 找到网页的title res = re.findall(r"<title>(.+?)</title>", html) print("\nPage title is: ", res[0])
# Page title is: Scraping tutorial 1 | 莫烦Python
# flags=re.DOTALL,使对tab、new line不敏感 # 如果去掉这个参数,则不能查找出所需内容 res = re.findall(r"<p>(.*?)</p>", html, flags=re.DOTALL) # re.DOTALL if multi line print("\nPage paragraph is: ", res[0])
from bs4 import BeautifulSoup from urllib.request import urlopen
## if has Chinese, apply decode() html = urlopen("https://morvanzhou.github.io/static/scraping/basic-structure.html").read().decode('utf-8') print(html)
打印出网页html
## 以lxml形式解析网页 soup = BeautifulSoup(html, features='lxml') ## 选择tag h1 print(soup.h1) ## 选择tag p print(soup.p) ## 返回所有的链接 all_href=soup.find_all('a') ## 生成一个列表 all_href = [l['href'] for l in all_href] print('\n', all_href)
from bs4 import BeautifulSoup from urllib.request import urlopen
## if has Chinese, apply decode() html = urlopen("https://morvanzhou.github.io/static/scraping/list.html").read().decode('utf-8') soup = BeautifulSoup(html, features='lxml')
## use class to narrow search ## 标签li中,class为中包含month的 month = soup.find_all('li', {"class": "month"}) for m in month: ## m为html形式 ## m.get_text()为网页显示的文字 print(m.get_text())
输出结果
一月 二月 三月 四月 五月
## 嵌套查找 jan = soup.find('ul', {"class": 'jan'}) d_jan = jan.find_all('li') ## use jan as a parent for d in d_jan: print(d.get_text())
from bs4 import BeautifulSoup from urllib.request import urlopen import re
## if has Chinese, apply decode() html = urlopen("https://morvanzhou.github.io/static/scraping/table.html").read().decode('utf-8') soup = BeautifulSoup(html, features='lxml')
## img标签中,src内容符合.jpg的内容 img_links = soup.find_all("img", {"src": re.compile('.*?\.jpg')}) for link in img_links: print(link['src']) ## 找到开头为https://morvan的链接 course_links = soup.find_all('a', {'href': re.compile('https://morvan.*')}) for link in course_links: print(link['href'])
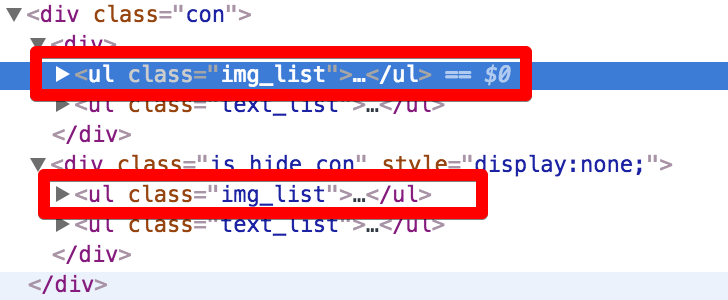
# 循环下载图片 for ul in img_ul: imgs = ul.find_all('img') for img in imgs: url = img['src'] r = requests.get(url, stream=True) image_name = url.split('/')[-1] with open('./img/%s' % image_name, 'wb') as f: for chunk in r.iter_content(chunk_size=128): f.write(chunk) print('Saved %s' % image_name)
爬虫加速
多进程加速式
import multiprocessing as mp import time from urllib.request import urlopen, urljoin from bs4 import BeautifulSoup import re
# DON'T OVER CRAWL THE WEBSITE OR YOU MAY NEVER VISIT AGAIN if base_url != "http://127.0.0.1:4000/": restricted_crawl = True else: restricted_crawl = False
while len(unseen) != 0: # still get some url to visit if restricted_crawl and len(seen) >= 20: break htmls = [crawl(url) for url in unseen] results = [parse(html) for html in htmls]
seen.update(unseen) # seen the crawled unseen.clear() # nothing unseen
for title, page_urls, url in results: unseen.update(page_urls - seen) # get new url to crawl
分布式方法
pool = mp.Pool(4) # 进程池 while len(unseen) != 0: # htmls = [crawl(url) for url in unseen] # ---> crawl_jobs = [pool.apply_async(crawl, args=(url,)) for url in unseen] htmls = [j.get() for j in crawl_jobs]
# results = [parse(html) for html in htmls] # ---> parse_jobs = [pool.apply_async(parse, args=(html,)) for html in htmls] results = [j.get() for j in parse_jobs]
classMofanSpider(scrapy.Spider): name = "mofan" start_urls = [ 'https://morvanzhou.github.io/', ] # unseen = set() # seen = set() # 我们不在需要 set 了, 它自动去重 classMofanSpider(scrapy.Spider): ... defparse(self, response): yield { # return some results 'title': response.css('h1::text').extract_first(default='Missing').strip().replace('"', ""), 'url': response.url, }
urls = response.css('a::attr(href)').re(r'^/.+?/$') # find all sub urls for url in urls: yield response.follow(url, callback=self.parse) # it will filter duplication automatically # yield 异步处理